Introduction
When you start developing the software, the codebase starts building up. Initially while it is small, it is easy to go through and change. However, as it keeps growing, it becomes more and more time consuming and complex to do that.
Many best practices also have evolved to tackle these challenges. However, it is still widely acknowledged that writing good applications takes maturity. The project success is highly person-dependent, as a Forbes article argues. As a result, companies compete fiercely to grab top-notch developers.
Most applications today are complex enough to be beyond one person. When multiple developers are involved, factors like how well they work together and how well they understand one another’s work also become important.
In such a scenario, there are many things that can go wrong. Many times they do. The problem itself is not visible in the first place until it is pretty late, and so appropriate corrective action cannot be taken in time. Important information is missing and is obscured away in the code. Project Managers operate blindfolded, and the success of the project hangs on a slippery edge.
The Problem
Why is the important information missing? Can it not be extracted from the code?
The more basic issue here is that a workable quantitative unit of measurement for sizing software applications, or their parts or individual feature, is absent.
-
Some may point to LOC (lines of code) as a metric for the source code. The metric of LOC can be extracted from the codebase easily. But LOC is known to be a poor indicator for number of reasons, and the information extracted from it can be misleading (reference).
-
On the other hand, using function points (or a similar measure of requirements) for sizing a software is also misleading. Function points are derived from the requirements. They measure the requirements (“what” to do) and not the implementation (“how” to do).
If a good unit of measure itself is absent, how can you have a system that can provide reliable inputs for project management?
The Solution
The solution emerges from the extreme componentization and visualization that Xsemble brings to the table.
-
Extreme Componentization: At the design stage, the application is broken into tiny Xsemble components. The development focus then gets transformed from coding a large complex application to coding a number of individual components. Xsemble components are independent of one another and hence can be coded in isolation.
-
Visualization: The Xsemble flow diagram is similar to a flowchart. It contains both the control flow and data flow of the application. It is thus a visual representation of how the software works. It also stays up-to-date as the software undergoes changes.
It is easy to see how these facilities can be used to bring transparency and predictability.
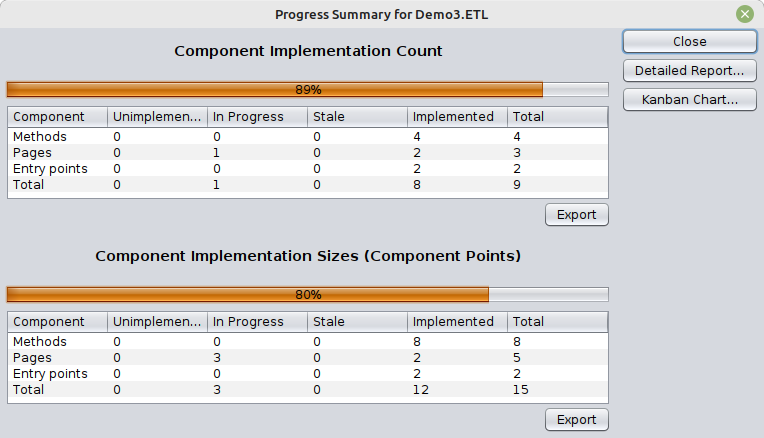
The way function points are a measure of functionality, we identify Component points as a measure of work. Components are assigned component points depending on their size and complexity. We use Fibonacci numbers corresponding to the T-shirt sizing of components:
- Extra Small (XS): 1 point
- Small (S): 2 points
- Medium (M): 3 points
- Large (L): 5 points
- Extra Large (XL): 8 points
Application to Quantitative Assessments
The component points lead us to quantitative measures, such as:
-
Sizing of features: Obtained by summing up the component points for the components involved in implementing the feature.
-
Percentage completion of work: Obtained by summing up the points of components that are complete and dividing by the cumulative size, into 100.
There are further ways to use the component points. For instance, the component points can be used to build the expectations of the defects expected and the amount of test cases required.
We conclude this article by showing an Xsemble dialog where the progress is shown in terms of component points (lower half).